
An insane capability to generalize
In our demo one can see that we trained Mr. Character to perform advanced transfer learning using for the training only Latin Alphabet. Why didn’t we use a richer data set?
This is because MENTAL has an insane capability to generalize.
MENTAL is founded in the theory of practopoiesis (Nikolić 2015).
An extreme form of transfer learning is one-shot learning i.e., learning from only a small number of examples. Recently research has been conducted on one-shot learning. Several solutions have demonstrated that one-shot learning is possible to implement. However, so far no solution has been found that is elegant and efficient enough to be wildly applied in practice. That is, except for the MENTAL technology.
Here we explain why.
Typically, one shot-training tasks for character recognition use the Omniglot training set, which consists of a total of 50 alphabets and 1623 different characters. A more challenging task and more useful technology is if AI can learn from a single data set. We posed that as the second one-shot challenge to our technology. Please read our “How does it work?” section for more details on our three-way one-shot challenge. To take on this challenge, we trained Mr. Character on the EMNIST data set that consist of only 47 different characters (build off of Latin alphabet and Arabic digits) having 2800 examples per character. That way we tested the generalization capabilities of our AI in the conditions that are much more human-like. No human needs be exposed to dozens of alphabets before being able to generalize to novel characters. Rather, a human is exposed to a limited set of symbols but a somewhat larger number of examples of those. This is how a useful AI should work. And this is exactly how our technology works.
Being able to learn to generalize from only 47 rather than from 1623 characters makes the generalization capabilities of Mr. Character 1623 / 47 = 34 times more effective than ‘competition’. When taking into account rotations of Omniglot character set (90°, 180°, 270°) that are often performed to even further expand the number of characters, this ratio becomes even bigger—Mr. Character becomes more than 100 times more effective.
Here is how MENTAL scores against other solutions to one-shot learning:
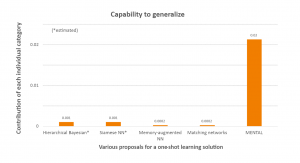
In the above graph, we compare MENTAL to other proposals to address one-shot learning: Hierarchical Bayesian (Lake et al. 2013), Siamese neural networks (Koch et al. 2015), Memory-Augmented Neural Network (Santoro et al. 2016), Matching Networks (Vinyals et al. 2016).
As you can see, MENTAL generalize much better than other approaches. As a result, it can solve a similar task with much fewer data points. Hence, we dare stating that, in that respect, Mr. Character is two orders of magnitude more capable learner to generalize than are some other approaches considered to be state-of-the-art in one-shot learning.
Note that there is nothing that specializes our technology for learning characters. The technology can be applied to any problem.
But we are not done explaining how capable MENTAL is in generalizing. MENTAL can generalize to one-shot performance capability from data sets that contain already quite a small number of examples. Below you can see the training performance of a one-shot generalization test with only seven example categories. An agent was trained to generalize from Arabic digits 0 to 6, to one-shot learning of digits 7, 8, and 9. It achieved an impressive performance already after a single training epoch on three example images. 1000 new images were then recognized with an accuracy of ~80% correct:
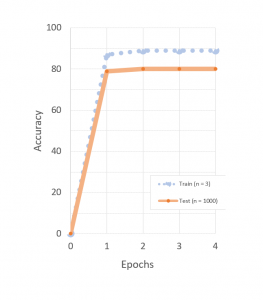
Our technology can generalize from scarce data sets. There is no a pre-requirement for a special data sets such as Omniglot in order to take advantage of MENTAL technology.
Also, MENTAL performs much better than transfer learning. The reason is that MENTAL imposes inductive biases, while transfer learning does not. It is the correct inductive biases that make it so powerful. MENTAL learns the inductive biases suitable for a given domain.
If this doesn’t impress you, check out the following. Once trained to learn fast, MENTAL agents expand the new knolwedge quite widely. The domain within which the new problems can stay is surprisingly general. For example, after having trained Mr. Character on Latin letters, he was not only able to learn other writing systems in a single shot; he was able to learn in one shot acronyms like these ones:

and simple object drawings like these ones:
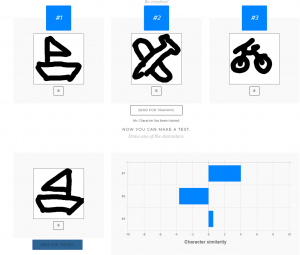
Don’t believe it? Check out the demo and challange Mr. Character with your own drawings.
MENTAL is the ideal enabling technology for AutoML.
References:
Koch, G., Zemel, R., & Salakhutdinov, R. (2015). Siamese neural networks for one-shot image recognition. In ICML Deep Learning Workshop (Vol. 2).
Lake, B. M., Salakhutdinov, R., & Tenenbaum, J. B. (2015). Human-level concept learning through probabilistic program induction. Science, 350(6266), 1332-1338.
Nikolić, D. (2015). Practopoiesis: Or how life fosters a mind. Journal of theoretical biology, 373, 40-61.
Santoro, A., Bartunov, S., Botvinick, M., Wierstra, D., & Lillicrap, T. (2016). One-shot learning with memory-augmented neural networks. arXiv preprint arXiv:1605.06065.
Vinyals, O., Blundell, C., Lillicrap, T., & Wierstra, D. (2016). Matching networks for one shot learning. In Advances in Neural Information Processing Systems (pp. 3630-3638).